

Bei der Seibert Group rollen wir gerade KI-Tools für knapp 500 Mitarbeitende aus, von der Entwicklung bis in die Buchhaltung. Dabei stellen sich Fragen, die vermutlich jedes Unternehmen beschäftigen, welches sich mit KI auseinandersetzt: Was tun, wenn Daten das Netzwerk nicht verlassen dürfen? Wie hält man die Kosten im Griff, wenn hunderte Mitarbeitende KI nutzen? Und wie gut sind selbst gehostete Modelle mittlerweile wirklich?
Also haben wir es ausprobiert: KI-Modelle auf eigenen Servern, jeweils einen Tag lang im echten Einsatz.
Warum Self-Hosted?
Die Idee kam nicht aus Neugier, sondern aus drei konkreten Gründen. Erstens: Kosten. Cloud-KI-Abos skalieren mit der Nutzerzahl, und bei knapp 500 Mitarbeitenden wird das ein relevanter Posten. Zweitens: Datenschutz. Bei Self-Hosted verlässt kein einziger Prompt das eigene Netzwerk, keine Trainingsdaten für Dritte, keine Abhängigkeit von externen Datenschutzversprechen. Drittens: Immer mehr Kunden fragen nach souveränen KI-Lösungen. Wenn wir dazu beraten wollen, müssen wir es selbst gemacht haben.
Zwei Modelle, zwei Tage
Wir sind den Test strukturiert angegangen: Hardware auswählen, Modelle auf eine Shortlist setzen, dann in mehreren Phasen testen, erst automatisierte Benchmarks, dann manuelle Tests durch echte Mitarbeitende mit echten Aufgaben.
Die Hardware: vier H200-GPUs von IONOS, gemietet für 12 Euro pro Stunde. Darauf haben wir an zwei aufeinanderfolgenden Tagen zwei unterschiedliche Modelle getestet.
Tag 1: Mistral Large 3
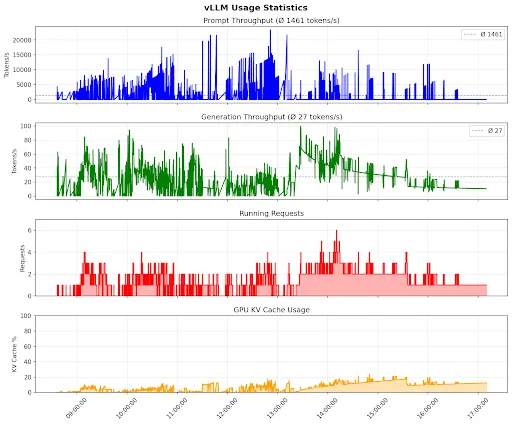
Ein Modell mit 675 Milliarden Parametern. Die Geschwindigkeit war beeindruckend, ein Kollege nannte es “Speedy Gonzales”. Bei einem Stresstest mit 500 parallelen Anfragen (jeweils 10.000 Tokens) blieb das System stabil. Aber: Die Tool-Integration mit Claude Code funktionierte nicht zuverlässig, und das Modell halluzinierte ohne ausreichend Kontext.
“Sehr gutes Modell, aber Claude macht den runderen Eindruck.” Fazit eines Testers
Tag 2: Qwen 3.5
Unser Favorit. 397 Milliarden Parameter, technisch ein sogenanntes Mixture-of-Experts-Modell (MoE): Pro Anfrage werden nur 17 Milliarden Parameter aktiviert. Das erklärt, warum es trotz seiner Größe so schnell ist.
Ein Entwickler ließ seine gesamte Codebase analysieren, in 2 Minuten. Mit Claude Sonnet, einem verbreiteten Cloud-KI-Modell, dauert das Gleiche 5 bis 6 Minuten.
Mehrere Teammitglieder beschrieben die Qualität als “sehr brauchbar”: Webapps bauen, Transkripte zusammenfassen, Ideen kategorisieren, alles funktionierte solide. Eigene Automatisierungen, Skills und automatische Codebase-Suche funktionierten problemlos.
Kosten und Kontextfenster
Beide Modelle boten ein Kontextfenster von 256.000 Token, genug, um auch längere Dokumente oder kleinere Codebasen auf einmal zu verarbeiten.
Für den gesamten Testtag lagen wir bei rund 120 Euro, und theoretisch hätten dutzende Mitarbeitende gleichzeitig damit arbeiten können, ohne Wartezeiten oder Drosselung. Im Dauerbetrieb entstehen mit vier Grafikkarten auf der einen Seite planbare, aber auf der anderen Seite auch hohe Kosten von etwa 8.000 Euro pro Monat.
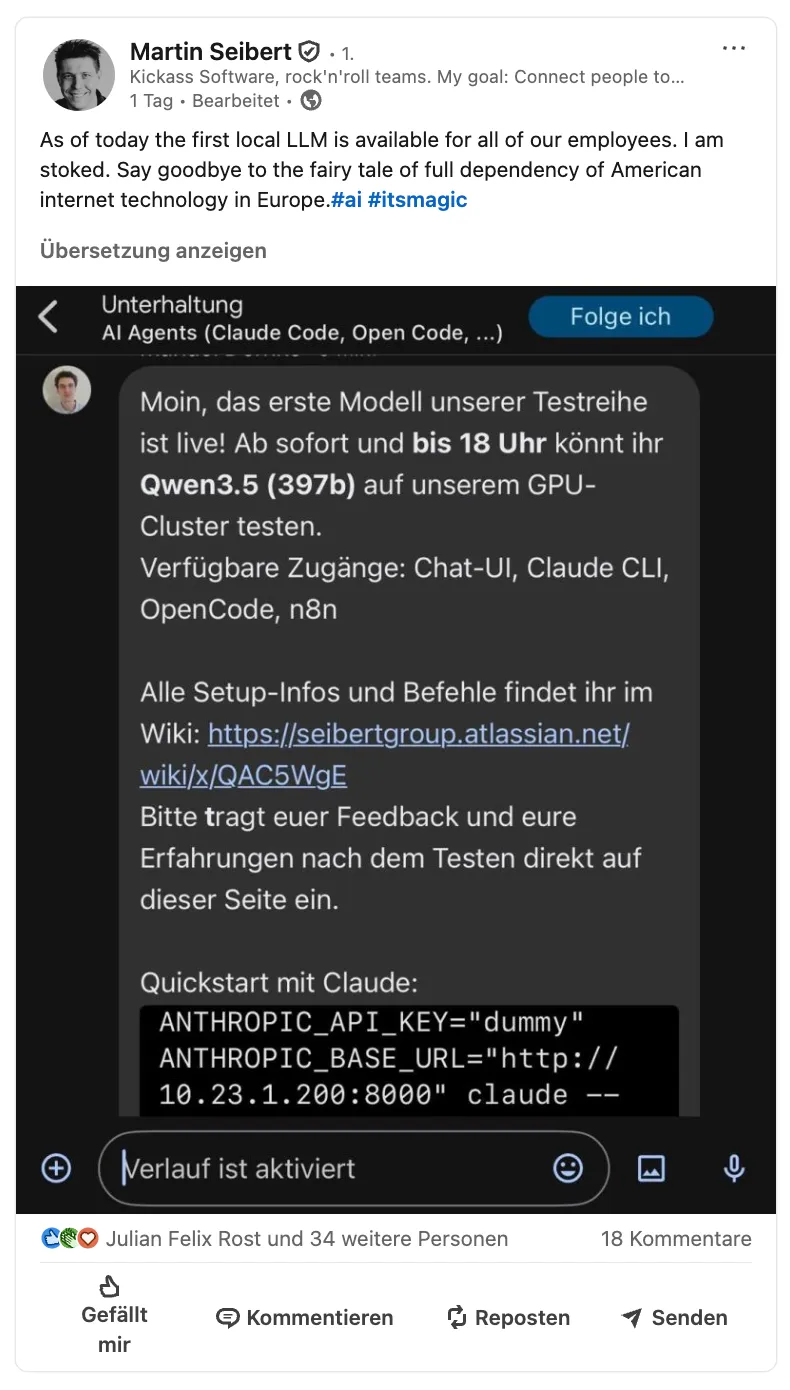
Unser CEO Martin Seibert hat den Test auf LinkedIn geteilt und viel Feedback bekommen:
Was noch nicht funktioniert
Wir könnten jetzt so tun, als wäre alles perfekt. Ist es nicht.
Bild- und PDF-Analyse fehlen komplett, die API-Schnittstelle unterstützt das aktuell nicht. Mehrere Tester haben es versucht, die Qualität lag bei null. Wer OCR oder Bildanalyse braucht, muss weiterhin auf Cloud-Modelle zurückgreifen. Ein Modellwechsel bedeutet rund 400 GB herunterladen und auf Treiberkompatibilität prüfen, das dauert ein bis zwei Stunden, spontan wechseln ist nicht. Und der Zugang läuft bisher nur über VPN, für den produktiven Einsatz braucht es eine richtige Authentifizierung.
Auf unserer Shortlist stehen noch weitere Modelle, darunter Llama 3.1 Nemotron Ultra. Das Ziel: herausfinden, welche Kombination aus Cloud- und Self-Hosted-Modellen für ein Unternehmen unserer Größe am besten funktioniert. Nicht entweder-oder, sondern beides, je nach Anwendungsfall.
Warum das für den Mittelstand relevant ist
Die Frage “Cloud oder eigene Infrastruktur?” stellt sich nicht nur bei klassischer IT. Bei KI wird sie gerade sehr konkret. Branchen wie Finanzen, Gesundheit oder öffentliche Verwaltung haben klare Regeln, wo Daten verarbeitet werden dürfen, Self-Hosted löst das Problem. Ab einer gewissen Nutzerzahl kann ein eigener Cluster auch günstiger sein als Token-basierte Abrechnung. Und man bleibt unabhängig: kein Vendor-Lock-in, keine plötzlichen Preiserhöhungen, keine API-Änderungen, die den eigenen Workflow zerstören.
Gerade in den letzten acht Wochen hat KI nochmal eine ganz andere Geschwindigkeit aufgenommen, neue Modelle, neue Möglichkeiten, neue Fragen. Cloud, Self-Hosted oder beides: Was wo sinnvoll ist, lernen wir jeden Tag dazu.
Genau diese Erfahrung steckt in unserem Programm “Agents in Teams”. In drei Monaten arbeiten wir mit 25 Mitarbeitenden aus deinem Unternehmen zusammen, um ihnen zu zeigen, wie sie KI-Tools produktiv und wertschöpfend einsetzen können. Sie werden so zu Multiplikatoren, die das Wissen ins gesamte Unternehmen tragen. Und gleichzeitig kümmern wir uns um Compliance, Governance und die Kosten-Frage.
Unverbindlich 30 Minuten sprechen – wir zeigen, wie der Pilot in der Praxis aussieht und besprechen, ob Cloud oder Self-Hosted für dein Unternehmen die passende Lösung sein kann.
Jetzt Termin vereinbaren